Cartels of Mediocrity
Reproducing a sociology simulation paper about social norms and the tendency towards low-quality exchanges and suboptimal outcomes.
The Unaccountability Machine1 by Dan Davies is broadly about how and why dysfunctional systems produce outcomes nobody seems to want. It also contains a tidy introduction to Cybernetics2 and ideas like the viable system model3 and requisite variety4.
Reading that got me interested in more systems and sociology topics, and eventually led me to these papers:
- The LL game: The curious preference for low quality and its norms (Gambetta & Origgi, 2012)5
- Social Norms and the Dominance of Low-Doers (Proietti & Franco, 2018)6
Despite knowing nothing about game theory, sociology, or behavioral modeling, I thought both papers were approachable and engaging. After 25 years in industry it was refreshing to see a formal academic take on organizational cliques. And the papers were timely with a few things in my life:
- I’d been prototyping some game ideas involving simulated agent populations and emergent behavior with my kid, and the second paper does exactly that
- I’d been looking for a reason to try Clerk7, a Clojure visual notebook tool
- It was performance review time at work
So I committed to reproducing the paper’s findings in Clojure and its tables/figures (plus new ones) using Clerk:
- Clojure source: https://github.com/taylorwood/low-doers
- Clerk notebooks: fundamentals and figures
The phenomenon
Professionally, have you ever felt like your hard work wasn’t furthering your career, or even irritating some colleagues? Ever thought things might be easier if you coasted a bit? Maybe you needn’t even feel bad about it if your peers had the same mindset.
The dissonance is reduced by interacting always with the same people, whom one can trust for not challenging one’s standards. L-doers segregate themselves in mutual admiration societies.
This is the mindset from which Gambetta & Origgi’s “cartels of mediocrity” arise. The LL game abstract:
We investigate a phenomenon which we have experienced as common when dealing with an assortment of Italian public and private institutions: people promise to exchange high quality goods and services (H), but then something goes wrong and the quality delivered is lower than promised (L). While this is perceived as ‘cheating’ by outsiders, insiders seem not only to adapt but to rely on this outcome. They do not resent low quality exchanges, in fact they seem to resent high quality ones, and are inclined to ostracise and avoid dealing with agents who deliver high quality. This equilibrium violates the standard preference ranking associated to the prisoner’s dilemma and similar games, whereby self-interested rational agents prefer to dish out low quality in exchange for high quality. While equally ‘lazy’, agents in our L-worlds are nonetheless oddly ‘pro-social’: to the advantage of maximizing their raw self-interest, they prefer to receive low quality provided that they too can in exchange deliver low quality without embarrassment. They develop a set of oblique social norms to sustain their preferred equilibrium when threatened by intrusions of high quality. We argue that cooperation is not always for the better: high quality collective outcomes are not only endangered by self-interested individual defectors, but by ‘cartels’ of mutually satisfied mediocrities.
And later in the LL game:
Our basic point so far can be summed up thus: if you give me L but in return you tolerate my L we collude on L-ness, we become friends in L-ness, just like friends we tolerate each other’s weaknesses. But if you give me H that leaves you free to disclose my L-ness and complain about it. So you are not my friend, I fear and resent you, and if I cannot punish you for producing H, at least I avoid dealing with you. While in an ordinary world it is L-doers who are punished by avoidance and exclusion, in an L-dominated world it is H-doers who are ostracised. Essentially, the L-exchange can be seen as a cartel of mediocrities who pretend to be H.
There seems to be two forces that could contrast our supposed natural inclinations to L-ness and promote quality, one is the passion for a job well-done, the intrinsic pleasure found in employing and testing one’s skills at some task; the other is competition, succeeding at which carries extrinsic rewards. Generically, these forces fail if the algebraic sum of rewards and punishments for H-ness is lower than the sum of rewards and punishments for L-ness. Even H-prone individuals are ultimately driven to choose L (or to become eccentric and isolated ‘perfectionists’ or to migrate) if they systematically fail to gain any reward from their effort. In short, L spreads if it pays off. This remains a tautology, however, unless we can understand the conditions that affect the relative payoffs of H and L.
I recommend reading the paper just for the examples of different H/L exchanges, their psychosocial underpinnings, and the colorful Italian anecdotes8.
Social Norms and Low-Doers takes these ideas further with social agent simulation in NetLogo9. After modeling the social decay of L-worlds, it tests different regimes of rewards/sanctions to foster high-quality exchange:
Social norms play a fundamental role in holding groups together. The rationale behind most of them is to coordinate individual actions into a beneficial societal outcome. However, there are cases where pro-social behavior within a community seems, to the contrary, to cause inefficiencies and suboptimal collective outcomes. An explanation for this is that individuals in a society are of different types and their type determines the norm of fairness they adopt. Not all such norms are bound to be beneficial at the societal level. When individuals of different types meet a clash of norms can arise. This, in turn, can determine an advantage for the “wrong” type. We show this by a game-theoretic analysis in a very simple setting. To test this result – as well as its possible remedies – we also devise a specific simulation model. Our model is written in NETLOGO and is a first attempt to study our problem within an artificial environment that simulates the evolution of a society over time.
The game
A society of agents that collaborate with each other, accumulate payoffs, age, retire, and get replaced by new hires over time. Their collaborations consist of a simple mutual exchange of abstract “goods”:
Assume for simplicity that goods can be produced at two levels of quality, High (H) and Low (L). H is both more rewarding to receive and more costly to produce than L; H takes more time, effort, skills and organisation.
Agents independently choose how much effort to put in: H (high) or L (low). Neither knows the other’s choice in advance. The four possible outcomes from any agent’s perspective:
| You | Them | |
|---|---|---|
| H | H | Quality work from both |
| H | L | You submitted quality work, they coasted |
| L | H | You coasted, they submitted quality work |
| L | L | Lazy slop from both |
Every agent has a type, which describes their ranking of preferred outcomes, e.g. HH > HL > LH > LL. All preference orderings of those four outcomes become 24 possible agent types in all, each classifiable along two axes: selfishness and mindedness. A type is selfish when free-riding (LH) is its top choice, and high-minded when it ranks mutual-high (HH) above mutual-low (LL).
All 24 types
| # | Preference (worst < best) | Selfishness | Mindedness | Name |
|---|---|---|---|---|
| 1 | HL < LL < HH < LH | selfish | high | hs1 |
| 2 | LL < HL < HH < LH | selfish | high | hs2 |
| 3 | HL < HH < LL < LH | selfish | low | ls1 |
| 4 | HH < HL < LL < LH | selfish | low | ls2 |
| 5 | LL < HH < HL < LH | selfish | high | hs3 |
| 6 | HH < LL < HL < LH | selfish | low | ls3 |
| 7 | LL < LH < HL < HH | non-selfish | high | hn1 |
| 8 | LH < LL < HL < HH | non-selfish | high | hn2 |
| 9 | LL < HL < LH < HH | non-selfish | high | hn3 |
| 10 | HL < LL < LH < HH | non-selfish | high | hn4 |
| 11 | LH < HL < LL < HH | non-selfish | high | hn5 |
| 12 | HL < LH < LL < HH | non-selfish | high | hn6 |
| 13 | LH < HL < HH < LL | non-selfish | low | ln1 |
| 14 | HL < LH < HH < LL | non-selfish | low | ln2 |
| 15 | LH < HH < HL < LL | non-selfish | low | ln3 |
| 16 | HH < LH < HL < LL | non-selfish | low | ln4 |
| 17 | HL < HH < LH < LL | non-selfish | low | ln5 |
| 18 | HH < HL < LH < LL | non-selfish | low | ln6 |
| 19 | LH < HH < LL < HL | non-selfish | low | ln7 |
| 20 | HH < LH < LL < HL | non-selfish | low | ln8 |
| 21 | LH < LL < HH < HL | non-selfish | high | hn7 |
| 22 | LL < LH < HH < HL | non-selfish | high | hn8 |
| 23 | HH < LL < LH < HL | non-selfish | low | ln9 |
| 24 | LL < HH < LH < HL | non-selfish | high | hn9 |
Proietti & Franco focus on two types to start: hs1 and ls1. Both are selfish (their top preference is giving L and receiving H) but they differ in their mindedness (which they’d prefer if selfishness isn’t on the table.)
- hs1 (high-minded) prefers mutual-high (HH) over mutual-low (LL). Starts out playing H.
- ls1 (low-minded) prefers mutual-low (LL) over mutual-high (HH). Starts out playing L.
Such agents are arguably likely to be found in a competitive society where individuals are incentivized to participate in many activities (for example improving their CV by publishing, teaching, participating to conferences and research projects) while at the same time economizing their efforts and getting the most out of them.
Payoffs follow the preference ordering:

Agents can reconsider their strategy after an exchange. Each agent tracks two running tallies per partner (which are reset whenever the agent changes strategy):
- Shortfall: cumulative gap between actual payoff and what both playing baseline would have earned.
- Balance: running difference between actual payoff and what the opposite action would have earned with this partner.
When the shortfall crosses a threshold, a negative balance triggers a switch in the agent’s baseline strategy.
The asymmetry for the hs1 vs ls1 collaborations is apparent from the opening play: hs1 starts at H and can fall short, but ls1 starts at L and in an LL exchange already earns its second-best outcome.
Exchange sequence diagram
sequenceDiagram
participant hs1
participant ls1
Note over hs1: plays H (baseline)
Note over ls1: plays L (baseline)
hs1->>ls1: H
ls1->>hs1: L
Note over hs1: earns 1 (sucker)
shortfall +2, balance −1
Note over ls1: earns 4 (free-rider)
Note over hs1: shortfall ≥ threshold
balance < 0 → switches to L
loop Every subsequent round
hs1->>ls1: L
ls1->>hs1: L
Note over hs1: earns 2, shortfall grows
but switching back to H
would only earn 1 --- stuck
Note over ls1: earns 3 (preferred LL)
end
The simulation
Proietti & Franco implement the model simulation in NetLogo, and I based my reproduction on their published source code10.
Each simulated year:
- Reset everyone’s annual earnings
- Retire the oldest agents and replace them with fresh ones
- Every pair plays one round; earnings are gated by a collaboration probability
- Age everyone
- Mark anyone past the retirement age for mandatory retirement
- Mark a bottom % earners for early retirement
The institution hires 50/50 from hs1/ls1. The mechanism that tips the balance is in step 6: ls1 agents systematically out-earn hs1 agents over time, so hs1 agents have shorter careers/earlier retirements. Try-hards burn out and low-doers inherit the org: fresh hs1 replacements (hired 50/50) start out playing H, get exploited again, and the cycle repeats.
The agent state is a plain map; the memory map is keyed by partner id and tracks the shortfall/balance running tallies.
(defn agent [id type]
{:my-id id :type-of-academic type :age 0 :total-payoff 0 :memory {}})
Each round, both agents decide independently whether to offer H or L, then record the exchange:
(defn play-round
([a1 a2] (play-round a1 a2 default-params true))
([a1 a2 params pays-out?]
(let [act1 (decide a1 (:my-id a2) params)
act2 (decide a2 (:my-id a1) params)
[p1 p2] (typ/payoffs (:type-of-academic a1)
(:type-of-academic a2)
[act1 act2])]
[(record-exchange a1 (:my-id a2) act1 act2 p1 pays-out?)
(record-exchange a2 (:my-id a1) act2 act1 p2 pays-out?)])))
The decide function implements the reconsider rule: an agent plays its baseline until shortfall crosses the threshold, then a negative balance flips it to the opposite action (H-to-L or vice versa.)
(defn- reconsidering? [baseline shortfall threshold]
(and (= baseline :H) (>= shortfall threshold)))
(defn decide
[agent partner-id {threshold :change-of-strategy-threshold
:keys [reward-tick? reward-pct sanction-pct reward-maxes]}]
(let [t (:type-of-academic agent)
base (typ/baseline-action t)
m (get-in agent [:memory partner-id])
last (:last-action m base)]
(if (reconsidering? base (:difference-from-optimal m 0) threshold)
(let [rb (if reward-tick?
(reward-balance t (:recon-exch m {})
(reward-prob (:window-hh agent 0)
(:max-hh reward-maxes))
(reward-prob (:window-ll agent 0)
(:max-ll reward-maxes))
(double (or reward-pct 0))
(double (or sanction-pct 0)))
0.0)]
(if (neg? (+ (:balance m 0) rb))
(other last)
last))
base)))
The reward-tick? branch is used later: when a reward/sanction regime is active, the expected reward/sanction differential (rb) is added to the balance before the switch test.
I think it’s important to note, as in the paper, the experiments below are conducted on a fully-connected network of agents and each connection has a probability of collaboration. Obviously this modeling approach doesn’t reflect more hierarchical or siloed organizational structures. To that end they also model scale-free networks where agents have fewer connections and find those conditions more favorable for hs1.
The outcomes
Given a society of 20 agents hired evenly from hs1/ls1, H actions begin around 20% of exchanges, then collapse to a ~9% steady state within the first decade or two and remain there for 1,500 simulated years.
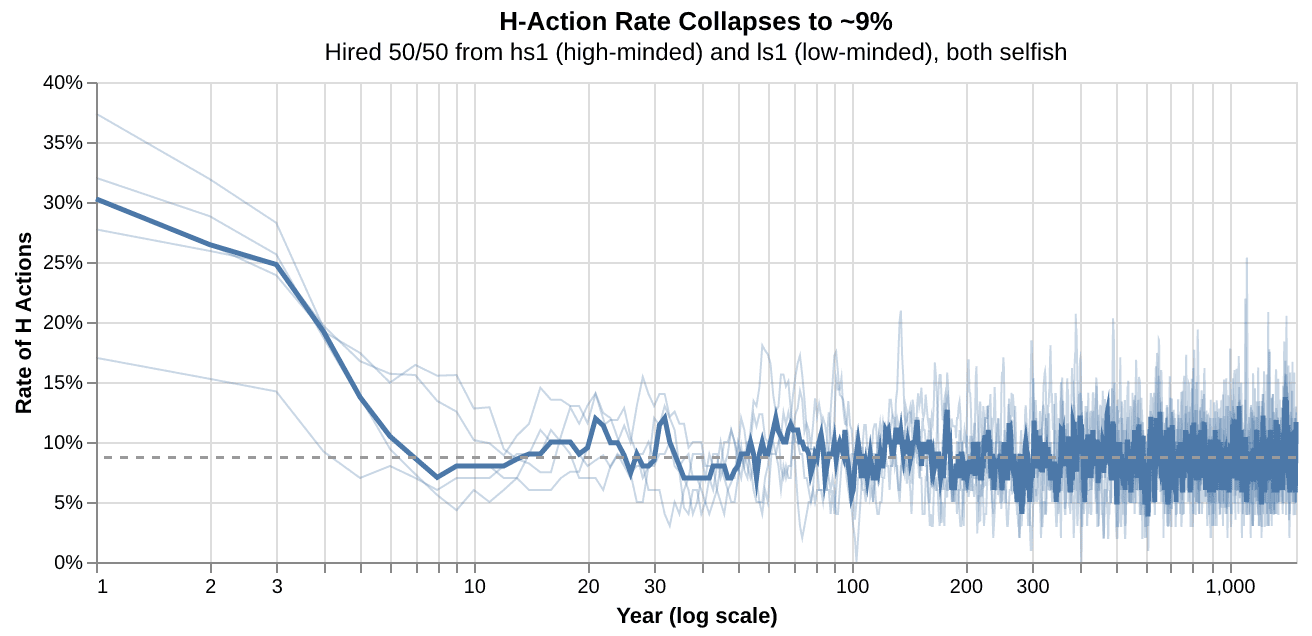
Career churn
The agent turnover driving that collapse shows up in the agent career tenures and retirement reasons. Plotting tenure-at-retirement, hs1 (left) piles up on the short end while ls1 (right) generally lasts longer.

hs1 dominates the early-retirement side (bottom-% earners forced out under sustained low payoffs), while agents that survive to the mandatory retirement age reach it at similar tenures regardless of type. ls1’s longer careers come from rarely capitulating to H, not from outlasting hs1 once it does.

Robustness
The paper’s finding holds across different simulation parameters for society sizes and strategy-change thresholds. (See original: 4.3)


Table 4 breaks that asymmetry by raising hs1’s LL payoff above ls1’s, so an hs1 stuck in mutual-low no longer trails its partner as it does under normal payoffs, yet the simulated outcome is largely unchanged. (See original: 4.7)

What can be done?
The paper tests two basic strategies for preventing the collapse into low-quality exchanges:
- Change who you hire: the society’s composition of H vs L, selfish and non-selfish
- Change their incentives: rewards for HH exchanges and sanctions for LL
Hiring filters
The first lever is the mix of agent types in the society. (See original: 4.10)

Unsurprisingly, hiring more hs1 agents helps, but as the paper notes:
Furthermore, it is quite challenging for a policy maker or employer to succeed in hiring such a high percentage of high-minded individuals.
Heroes & Saints
What works better is changing the kind of high-minded agent you hire. These two non-selfish, high-minded types protect the H equilibrium:
- hn1 (hero): always plays H, even as the sucker, though it still ranks free-riding (LH) on top in preference.
- hn2 (saint): same behavior as the hero, but goes further and ranks LH below LL, so it wouldn’t even want to exploit.
Both types resist the capitulation mechanism entirely: since they always play H regardless, their shortfall/balance never push them to capitulate. Swap hs1 for either and the H-rate hovers around 50%.
Under such conditions, the efficiency of an institution can be sustained if high-minded people are not selfish, we may call them “heroes” or “saints”.
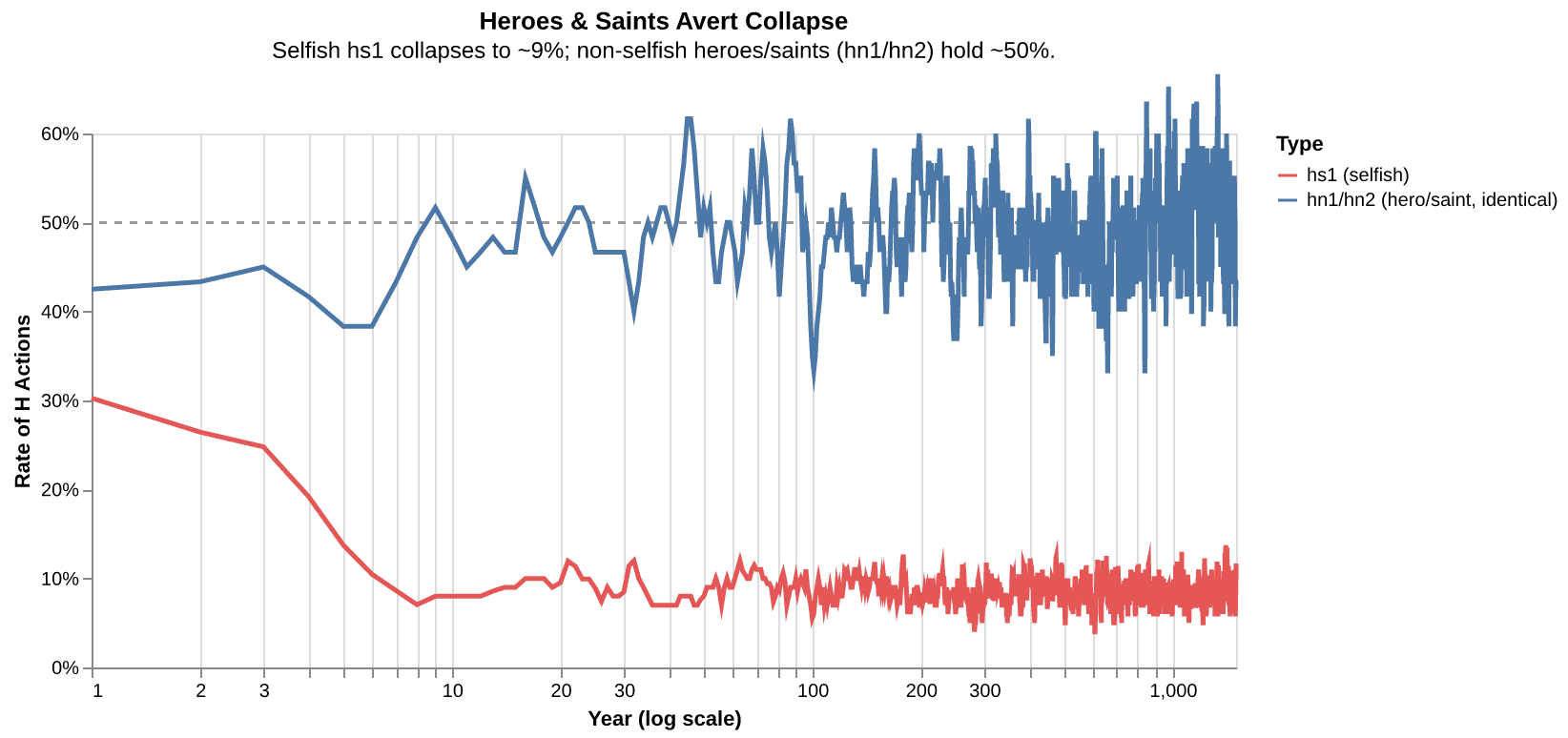
Reliably hiring a smaller contingent of heroes (hn1) and saints (hn2) may be more effective than hiring mostly high-minded, selfish agents (hs1), but it is similarly challenging for most organizations; mathematically, we can’t all work “the best of the best.”
Rewards & Sanctions
The second lever leaves the agent mix alone and changes the incentives (the reward-tick? branch of decide above).
As it turns out, rewarding HH exchanges has little effect, but sanctioning LL exchanges pulls capitulated hs1 agents back to H: the looming penalty enters the reconsider calculation and tips the balance.
Frequency also matters: sanctions every round push H-rates above 65%, while sanctions every three rounds barely help at all. Sanctioning LL is what helps. Frequent sanctions help more (bottom-left), and hiring more hs1 pushes the effect toward ~90% (bottom-right).

Each panel plots the steady-state H-rate against LL-sanction strength; color is the HH-reward. Top row sanctions every third year (f=3), bottom row every year (f=1); left column hires 50% hs1, right column 65%. Error bars are 95% CI over 5 seeds.
Sanctions only fire when an agent is in range of a reconsideration, so the more hs1 agents you start with, the more often the penalty has something to penalize. Hiring 65% hs1 lifts the baseline and reduces the sanction-frequency impact, recovering much of the sanction benefit even at the every-three-years cadence where 50/50 hiring collapses.
With selective hiring and balanced incentives, the H-rate climbs to ~90% (which is the most effective policy tested in the paper.)
Takeaways
These papers model societies/organizations that tend toward an equilibrium where low effort becomes pro-social behavior despite the undesirable outcomes. They contend “cartels of mediocrity” form against those offering higher quality exchanges.
To my mind, the top insight is that pro-social conformists and disillusioned try-hards (not free-riders) are the true drivers of decay: agents who’d genuinely prefer mutual excellence get captured by a social norm, “rationally” capitulating once sufficiently exploited. The high-minded burn out earlier and churn, and are replaced with new hires, keeping the organization flush with new subjects.
The secondary insight would be that sanctions on low-quality work are far more effective than rewards for high-quality work.
My suggestion when faced with organizational dynamics like these is to take pride in doing high-quality work even if peers do not! (But also, work within your means11. Don’t sacrifice your sanity and burn out.)
Notes
-
The Unaccountability Machine press.uchicago.edu
Also includes some history of cyberneticist and business-management consultant Stafford Beer12, who coined the phrase “the purpose of a system is what it does.” For a deeper review of the book, I recommend this blog, which also has a bunch of other interesting software posts. ↩ -
Wikipedia: Cybernetics
Note: the term cyber here is unrelated to computing. ↩ -
Wikipedia: Viable system model
A model of the organizational structure of any autonomous system capable of producing itself. ↩ -
Wikipedia: Law of requisite variety (cybernetics)
This felt immediately familiar to me from previous work on automation systems. ↩ -
Gambetta & Origgi, “The LL game: The curious preference for low quality and its norms” (2012) doi.org/10.1177/1470594X11433740 ↩
-
Proietti & Franco, “Social Norms and the Dominance of Low-Doers” (2018) jasss.org/21/1/6
Note: the PDF version appears to have accidentally duplicated Figure 2 as Figures 3 and 4 too. ↩ -
github.com/nextjournal/clerk Note: I initially wrote/developed this in a Clerk notebook, but this post is basically that notebook converted to Markdown with diagrams exported to SVG. ↩
-
There exists a fraudulent business in Southern Italy of adulterated olive oil made up mixing hazelnut and sunflower-seed oil, sold under the label “extra-virgin olive oil”. When Leonardo Marseglia – director of the Casa Olearia company in Apulia – was charged with contraband and fraud against European Union (and then acquitted) for having sold bogus oil under the label “extra virgin”, he justified himself in an interview by arguing that thanks to his adulterated oil many people could afford to buy oil with the label “extra virgin” at a reasonable price. Some people, he claimed, are interested in having at least the image of H-ness. “We pretend to buy good olive oil and you pretend to sell it”.
-
comses.net/codebases/5120 NetLogo source model from Social Norms and the Dominance of Low-Doers ↩
-
You must always work not just within but below your means. If you can handle three elements, handle only two. If you can handle ten, then handle five. In that way the ones you do handle, you handle with more ease, more mastery and you create a feeling of strength in reserve.
– Pablo Picasso -
Wikipedia: Stafford Beer
Interesting aside: nearing retirement he wanted to pass the Cybernetics torch onto none other than Brian Eno, who went on to record hits like the Windows startup sound and some of my favorite albums. ↩